
Who will be the right audience to study Hadoop Administration?
Last updated on Jun 11, 2020

Hadoop is an open source Apache framework in java written that to allows distributed processing on huge datasets among clusters of computers by using basic simple programming models. Application framework of hadoop operated in an environment to provide distributed storage and computation across clusters of computers. Hadoop designed for scale-up on a single server to thousands of machines is offering local computation and storage with Hadoop Administration.
Interested in learning Hadoop? Check the Hadoop admin online course
Hadoop Architecture:
Hadoop has two major layers in a core namely They are:
• Processing and computation layer for Map Reduce • Storing layer on Hadoop Distributed File System
Map Reduce: Generally Map Reduce means parallel programming model on writing distributed applications for efficient processing on a huge amount of data in large clusters to commodity hardware in reliable and fault-tolerant manner program runs on Hadoop is an Apache open-source framework.
Hadoop Distributed File System: Hadoop Distributed File System provides distributed file system is designed to run on commodity hardware. It has various similarities with existing systems and highly fault-tolerant designed to be deployed on less cost hardware also providing high access to application data is suitable for applications having large datasets
Apart from above mentioned two core components Hadoop framework also includes following two modules:
Hadoop Common: These ajava libraries required utilities on other Hadoop modules.
YARN: It is a framework for job scheduling and cluster resource management.
Hadoop Administration
Hadoop address ‘big data’ challenges and big data creates large business values today $10.2 billion worldwide revenue from big data analytics in 2013.
In particular Big data challenges face from various industries without an efficient in data processing approach and the data cannot create business values
Many of them were creating a large amount of data that they are unable to gain any insight from.
How Will Hadoop Works:
It is expensive to build bigger servers with a heavy configuration that handle large scale processing is an alternative for tie together many commodity computers with single CPU as single functional distributed system and practically clustered machines will read the dataset in parallel and provide a higher throughput. In Addition It is cheaper one high-end server and the first motivational factor behind using Hadoop that runs across clustered low-cost machines.
||{"title":"Master in Hadoop Administration ","subTitle":"Hadoop Administration Training by ITGURU's","btnTitle":"View Details","url":"https://onlineitguru.com/hadoop-online-training-placement.html","boxType":"reg"}||
Specifically Hadoop runs code according to on the cluster of computers. The process includes following core tasks that Hadoop performs:
• Initially data is divided into directories and files. Files separated into uniformly sized blocks of 128M and 64M. • These distributed files are across various cluster nodes for further processing. • HDFS are being on the top of a local file system and supervises the processing. • Blocks replicated on handling hardware failure. • Checking the code successfully executed. • Stored data was sending to a certain computer. • Debugging logs are writing for each job. • Performing the sort take place between map and reduce stage.
How Will Hadoop help in your career growth?
Increasing the popularity of Hadoop and analytics the professional having good grasp of Hadoop-related technologies have the greater possibility to grab career opportunities in this area.
For instance Learning Hadoop good choice for building career there will huge skill gap will formed in coming years and having knowledge on the proper technology will be your career success.
At the same time Become a Certified Hadoop Administration Online Course Enroll Now!
Who will be the right audience to study Hadoop?
It doesn’t matter the education background everyone is capable of doing analysis. for example, furthermore we do some other type of analysis in our daily life like shopping for cars, homes etc.
Now coming back to Hadoop all the techies have staked their claim to everything technical but there added advantage. For instance they must have some basic knowledge on oops concepts, statistics, and SQL.
What is a scope of Hadoop?
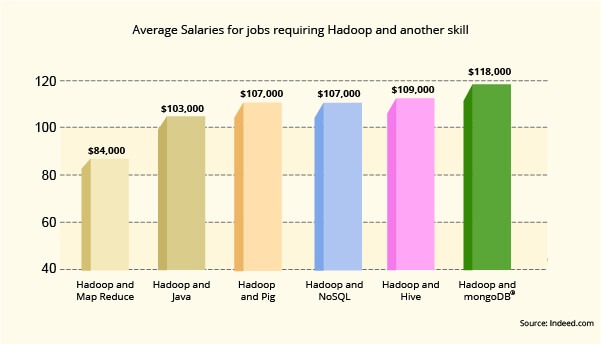
From the below mention graph is clearly visible that the daily rate of Hadoop jobs has increased dynamically over the last six years. According to research conducted on Hadoop growth and the above Average Salary for Hadoop and Hive $109, 00 and Similarly, the Top Highest Salary for Hadoop and MongoDB $118,000 and also Average Salary for the Hadoop and NoSQL $107, 000.
At the same time Hadoop admin must required for cluster balancing, node management, and their similar tasks has good scope in future as well many companies require Hadoop admin for their Hadoop projects. As a matter of fact forward Hadoop may also use in HDFS only data storing purpose.
Recommended Audience:
• System Administrators and programming developers. • Learn new techniques of maintaining large data sets by a project manager. • Basic level programmers and working professionals in python, C++, to learn the Hadoop admin online course. • Architects, Mainframe Professionals & Testing Professionals.
Prerequisites:
• Recommend to have initial programming language experience in Linux operating system and Java. • Fundamental command understanding basic knowledge on UNIX and SQL scripting will be useful to grasp concepts of Hadoop. • Simultaneously Developing Map-Reduce application for strong algorithm skill.