
Apache Spark, a open source clustered frame work developed in the year 2009 and released in the year 2010. It based on Hadoop Map Reduce and extends Map reduce model to efficiently use for more types of computations , which includes memory cluster computing. That increase the processing speed of an application. It is a general purpose engine for large scale data processing .
It supports rapid application for big data which allows code code reuse across batch , streaming and interactive applications .It s most popular use cases include building data pipe lines and developing machine learning models. Its core , the heart of the project provides distributed task transmissions, I/o functionality and scheduling with a potentially faster and flexible alternative to Map Reduce. Spark developers says that , when processes , it is 100 times faster than Map Reduce and 10 times faster than disk. Apache Spark requires cluster manager .
Get in touch with OnlineITGuru for mastering the Big Data Hadoop Online Course
Apache Spark requires a cluster manager and a distributed storage system. For cluster management spark supports Stand alone, Hadoop YARN. For distributed storage it can interface with wide variety which includes Cassandra , Hadoop Distributed file System, Map Reduce. In cases like where storage is not required and local file system can be used instead it supports pseudo distributed local mode for development and testing purposes . In such cases , Spark runs on a single machine with one executor per CPU Core .
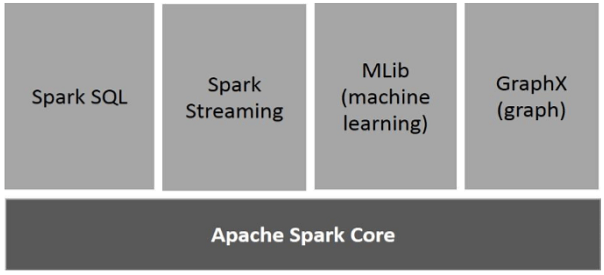
Components :
The Apache Spark has following components . Lets us discuss each in detail.Apache Spark Core:
it is the main component of Spark which is used as a general execution engine for spark platform where all the other functionality for Spark is built upon . It provides the In- memory computing and referencing data sets in external storage systems.
Spark SQL:
It is a component that built on the top of Spark core for the purpose of new data abstraction called Schema RDD . It that provides support for Structured and Semi Structured data
Spark Streaming :
It maintain Spark cores fast scheduling capability to perform Stream data analytics. It performs transformation of data by taking data in mini batches and performs RDD ( resilient distributed data bases ) on thos data .
MLlib(Machine Learning Library ):
It is a distributed machine learning framework which was placed above spark because of is distributed memory based architecture . It was designed against the Alternative Least Squares implementations . it has high efficiency which is nine times as fast as Hadoop disk based version of Apache Mahout.
Graph x :
It is a distributed graph processing framework built on the top of Spark. It Provide API for expressing Graph computations which can model user defined graphs by using Pregel Abstraction API.
Working:
Apache Spark has a capacity of processing data from a variety of data repositories like Hadoop distributed File system , No Sql Databases and Relational Data bases such as Hive . The performance of Big Data analytics applications can be increases by Apache Spark in memory processing , but it can also perform conventional disk based processing when the data is too large to fit into the existing memory .
Features :
The features of Spark were discussed below:Speed :
Spark process the data with a great speed . It can run applications in a Hadoop cluster up to 100 times faster in memory and 10 times faster when running on disk. As a matter of fact the greatest advantage of Spark that we can reduce the number of read /write operations on the disk. It stores the intermediate processing data in the memory .
Stand Alone :
Spark standalone means it occupies the place on the top of Hadoop distributed File system and space is allocated for HDFS , explicitly. Here Spark and Map Reduce run Side by side to cover all the spark jobs on cluster.
Hadoop Yarn :
Generally the major advantage of spark is that it allows Yarn without any pre-installation or root access required . It helps to integrate spark with Hadoop Ecosystem or Hadoop. It allows other components to run on the top on stack.
Advanced Analytics :
Especially Spark supports queries from Map and Reduce along with SQL queries , Streaming data , Machine Learning and Graph Algorithms.
Recommended Audience :
Software developersETL developersProject ManagersTeam Lead’sBusiness AnalystPrerequisites:
There is nothing much prerequisite for learning Big Data Hadoop .It’s good to have a knowledge on some OOPs Concepts . But it is not mandatory .Our Trainers will teach you if you don’t have a knowledge on those OOPs Concepts
Become a Master in Spark from OnlineITGuru Experts through Big Data Hadoop online course