
Hadoop basically has three main components
HDFS: It is used for storage of data
MapReduce: It is used for processing the stored data.
YARN: It is used for resource management

Processing with Map reduce
Map reduce involves processing on distributed data sets. Map reduce computation has two phases:
A map phase and reduce phase
During the map phase input data is divided into large number of pieces each of which is assigned to a map task which are distributed across the cluster
This map task performs the required computation on the data across each cluster and generates intermediate result
The intermediate result is sorted and again partitioned into number of pieces matching the number of reduce task
The reduce task are also distributed across cluster which process the data assigned to it and produces final output data and write it to HDFS.
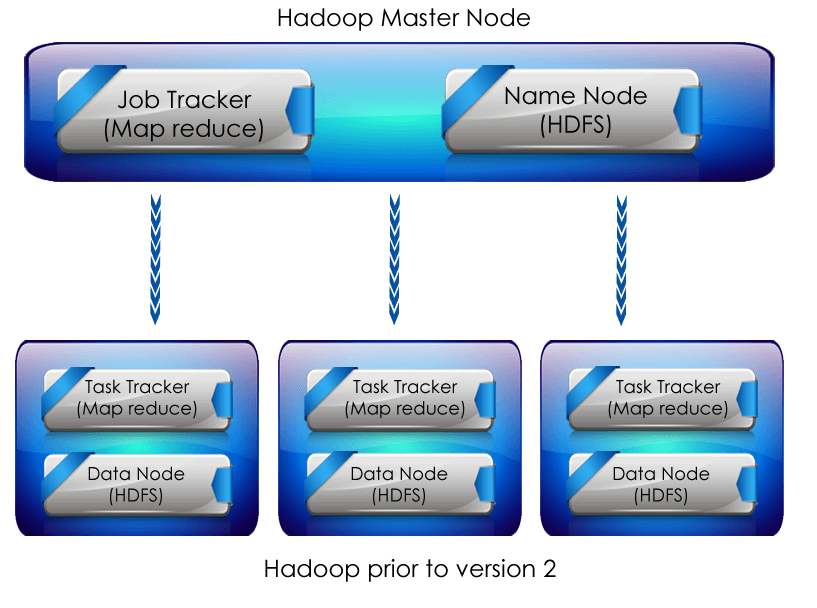
Map reduce framework has single Job tracker residing on master node and Task Tracker on the slave node
Job tracker: It is responsible for scheduling the components of job task on slaves and monitoring it.
Task tracker: It is responsible for executing the task assigned to it by master and provide the status of task assigned to the master periodically. :
HDFS
HDFS stands for Hadoop Administration online training Distributed File System.
HDFS is based on Google file system and provides distributed file system that is designed to run on large clusters,
HDFS also has master and slave architecture
Name Node: This is basically the master service which controls access to data files
Data Node: They are basically distributed as one per node in the cluster and are the slave services.
Data nodes manage the storage and client read and write request on the node in which they run.
Like any other file system HDFS provides shell and has list of commands to interact with the file system.


Before Hadoop version 2 for resource management they had a master service called a Job tracker and many slave service called TaskTracker for each node in cluster.
A map reduce job was assigned to a job tracker which placed it in a queue. Thismap reduce jobs where assigned to task trackers by job tracker based on the scheduling rules defined by the administrator
Job tracker could only run MapReduce Hadoop version 2 introduced YARN for resource management. YARN stands for Yet Another Resource Manager. So previous to Hadoop version 2 map reduce was used for data processing and resource management but from Hadoop version 2 YARN was used for resource management and Map-reduce was used for processing.
YARN
YARN provides generic resource management and scheduling service so that we can run more than map reduces applications on your computer.
YARN basically has two components that is Resource Manager and Node manager
Resource manager
It is one for each cluster.
It runs on master machine .It has two components
Scheduler: It is responsible for allocating resources to various applications
Application manager:It is responsible for accepting job submission and negotiating container for running the application.
It also keeps track of Node manager
Node Manager
It is one for each node and runs on slave machine
It is responsible for managing container and monitoring resource utilization in each cluster.
Are you interested in learning Big Data Hadoop Online Training from Bangalore? Connect to Online IT Guru and get a Professional training on Big Data Hadoop Training Course from Hyderabad.