
Machine Learning Pipelines:
A Machine Learning Pipeline is a high-level API for ML Lib that is in spark.ml package. We create Machine Learning Pipelines to convert the series of data from the original data format, to a piece of important valuable information.
It gives a technique to construct a multi-ML parallel pipeline system. This, in turn, helps to view the outputs of various ML methods.
Get the best knowledge on Machine learning by live industry experts at Machine Learning online training.
How does a Machine Learning Pipeline Works?
A Machine Learning Pipeline has many stages. Every pipeline stage contains the data processed from its previous stage. This means the result of a processing unit is given as an input, to the next stage.
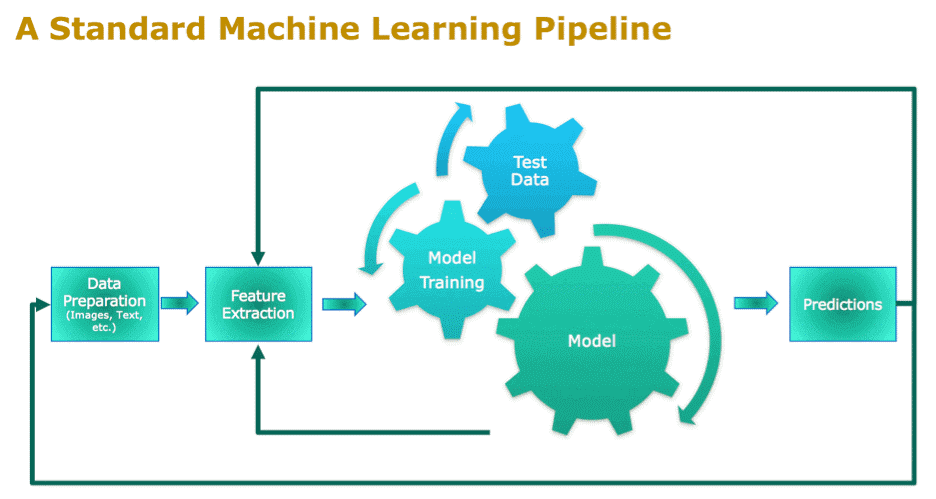
It has four important stages. They are
Pre-processing:
Firstly, in this stage, raw data is converted into an understandable format. Generally, Real-time data is not complete and inconsistent. It doesn’t have specific features or trends, and mostly they are not correct.
This process of getting the data is useful for a machine learning algorithm. This process involves steps like Feature Extraction and Scaling, Feature Selection, Dimensionality reduction, and sampling.
As a result, the output of the Data Pre-processing stage is the final data output. We use this output data to train the model, and also for testing purposes.
Learning:
Secondly, the system learns from the data given to it. Learning algorithms helps in processing understandable data. As a result, this helps in getting patterns. We can apply these patterns in a suitable situation.
The main goal of the learning algorithm is to use a system, for a particular input-output transformation function.
To perform this, we have to select the best model from a group of models. These models are given by various parameter settings, cross-validation, and metrics methods.
Evaluation:
In the evaluation stage, we calculate the performance of the machine learning model. For this, we set a model for the training data and find the labels of the test set. And then find the number of wrong estimations on the test dataset. As a result, this helps in calculating the accuracy of the model’s estimation.
Prediction
Lastly, in this stage, we predict the outputs. The performance of the model helps in finding the output of the test data set. Using the output, we can easily make predictions.
Why do we use a Machine Learning Pipeline?
The main aim of ML pipelines is to improve Business productivity and make better decisions.
Using ML Pipelines, machines start learning from algorithms. Therefore, this helps companies to find hidden patterns. These patterns help companies to make better choices.
The reasons for using ML Pipelines are given below.
Transforming industries – Machine learning pipelines provide important analysis in real-time. Therefore, this helps in transforming the industries. Fast Processing – Using ML algorithms, data processing from different sources is done very fast. So, this helps in providing Real-time predictions that are very useful for businesses. Time Analysis and Assessment – It helps in understanding the behaviour of the customer. For this, we use customer acquisition and Digital marketing techniques.
Advantages of Machine Learning Pipeline:
ML Pipelines have many advantages. They are
Extensible: We can create a new feature, by dividing the system into pieces. Therefore, we can say ML Pipelines are extensible. Scalable: Every part of the calculation is represented using a standard interface. So, if there is an issue with any part, we can measure that component separately. Therefore, it is Scalable. Flexible: We can easily replace the computation parts. To improve their usage, we can rework on that particular part, without making any changes to the other parts of the system. Therefore, we can say it is flexible.
Application of Machine Learning Pipeline:
These days, many industries working with huge data are applying machine learning techniques to get insights. Therefore, these insights help businesses to increase their efficiency.
Let us see the applications of the Machine Learning Pipeline in different sectors.
Marketing and Sales – Website suggestion items use ML Pipeline techniques. These techniques help in analyzing the history of the customers. Therefore, by using this we can know the customer’s interest. Healthcare – ML Pipelines help medical experts to examine the data and find the patterns. Therefore, this helps in finding and treating any medical issues. Oil and Gas – ML Pipelines help in Oil and Gas fields to find new energy sources, analyze the mineral availability in the ground.
Therefore, this makes it more effective and cost-effective.
Learn Machine Learning course online with OnlineITGuru experts in real-time.
Government – Government companies like Public Safety, also use Machine Learning Pipeline. This helps with mining different sources of data. So that we get insights.
For example, by examining the sensor data, we can find a process to improve efficiency and save money.
Financial Services – Financial industries like Banks and other businesses, use ML Pipelines. They help to find important insights into the data and prevent any fraud activities.
These insights help to find customers with high- risk profiles or can use cyber observations to give alert signs of any frauds.
Hence, these are the various applications of Machine learning pipelines.
I hope you understood about Machine Learning Pipelines. In my next blog, I will share how to build Machine Learning Pipelines.