
So till the previous blocks, we people created users, roles as well as the policies. And all these data must be stored in a safe manner for further retrieval. Moreover, the need for storage is increasing day-to-day. Therefore building and maintaining your own repositories has become a difficult job. Because it is a difficult task, to predict the amount of capacity needed in advance. So to overcome this kind of problem Amazon offers the internal storage through S3. So in this block, we will discuss AWS S3 in detail.
What is Amazon S3?
Amazon S3 is an abbreviation for Simple Storage Service (S3). This Amazon S3 is a storage on the internet. This Amazon S3 is responsible to store and retrieve any amount of data at any time on the web. People can use this storage platform, through the AWS Management sole. This platform is designed for the large capacity, low-cost storage provision across the multiple geographical regions. S3 provides the developers and IT teams with secure, durable and highly scalable object storage. This platform allows users to upload, store and download any type of files up to 5TB in size. This service allows subscribers to access the same systems that Amazon uses to run on its own websites.
Click the link to learn How to learn AWS Storage Classes:
S3 storage classes were meant to assist the concurrent loss of data in one (or) two facilities. These storage classes maintain data integrity using checksums. Besides S3 provides the life cycle management for the automatic migration of objects. Besides, Storage classes were also responsible to distinguish between the use case of the particular object in the bucket. Amazon S3 supports various types of storage classes. Let us discuss them in detail.
S3 standard :
standard storage class stores the data redundantly across multiple devices. And it is responsible to sustain the loss of 2 facilities concurrently. While uploading the files, if no storage class is specified, Amazon considers the Standard as the default storage class. Moreover, it provides low latency and high throughput performance. And it is designed in such a way that, it provides the 99.99% availability and 99.99% durability.
S3 standard - IA:
IA stands for the infrequently accesses data. This class is used when data is accessed less frequently. But it required rapid access when needed. And it has a lower fee when compared to S3. Moreover, it is capable to sustain the loss of 2 facilities concurrently. Besides S3 provides low latency and high throughput performance. And it has 99.99% availability and 99.99% durability.
S3 one -zone infrequent access:
This storage class is applied where the data is less accessed less frequently but requires rapid access when needed. It stores the data in the single availability zones rather than the other storage classes which store the data in a minimum of three availability zones. So it costs 20 % less when compared with standard IA storage class. Besides, it is a good choice to store backup data. It is a cost-effective region which is replicated from other AWS region using the S3 Cross-region replication. In a single availability zone, it has 99.5 % of availability and 99.99 % objects durability. This provides lifecycle management for the automatic migration of objects to other storage classes.
S3 Glacier:
It is the cheapest storage class, but it can be used for archive only. When compared to the other storage classes, here you can store any amount of data at a lower cost. This storage class allows you to upload the objects directly. Across the multiple availability zones, it is designed for 99.99999% durability. This storage class provides the three types of models:
- Expedited:
In this model, the data is stored for a few minutes and it charges very high
- Standard:
This model has a retrieval time of 3 to 5 hrs.
- Bulk:
The retrieval time of this model is 5 to 12 hrs.
S3 Intelligent Tiering:
It is the first object storage class, that delivers the automatic cost savings by moving the data between the two access tiers when the access pattern change. These tiers are frequent as well as the infrequent access. This storage class stores the object in two access tiers. It utilizes the first tier to optimize for frequent access. And the second tier to optimize for the infrequent access. It is designed for 99.99 % availability and 99.99 % durability.
One Zone IA:
It is the suggestable storage class designed for customers who want a lower cost option to the Infrequently accessed data. It is intended for the use cases with infrequently accessed data such as storing the backup copies of on-premises data. In this storage class, customers can now store the infrequently accessed data within a single availability zone at 20 % lower cost than the standard -IA.
What kind and how much amount of data be stored in S3?
In S3, you can store virtually any kind of data. Amazon S3 can store the large volume and many numbers of objects.' Amazon S3 can be employed to store any type of object. This platform can store internet applications, back up and recovery.
How data is organized in S3?
Data in S3 is organized in the form of buckets.
A bucket is a logical unit of storage in S3.
A bucket contains the objects which contain the data as well as the metadata.
Click the link to Know about What is AWS CertificationWhat is an Amazon Bucket?
Amazon S3 has two primary entities named buckets and objects. Buckets were responsible to store the objects. And these buckets have the flat hierarchy. Today every organization needs data in an ordered fashion. So Amazon introduced S3 to maintain the data in a traditional manner. And these buckets were capable of storing the different kinds of objects in the cloud. This platform allows users to upload the folders as well as the objects/files. Amazon platform allows the users to create a maximum of 100 buckets. Since these buckets were accesses globally, these bucket names must be unique. Moreover, I personally suggest the users follow the DNS naming conventions. i.e all letters should be in lowercase.

So let us see how to create the bucket in practical.
Bucket Creation:
step -1 :
Log in to the AWS Console and search for S3 and click on it. Then you will be entering into the following screen.
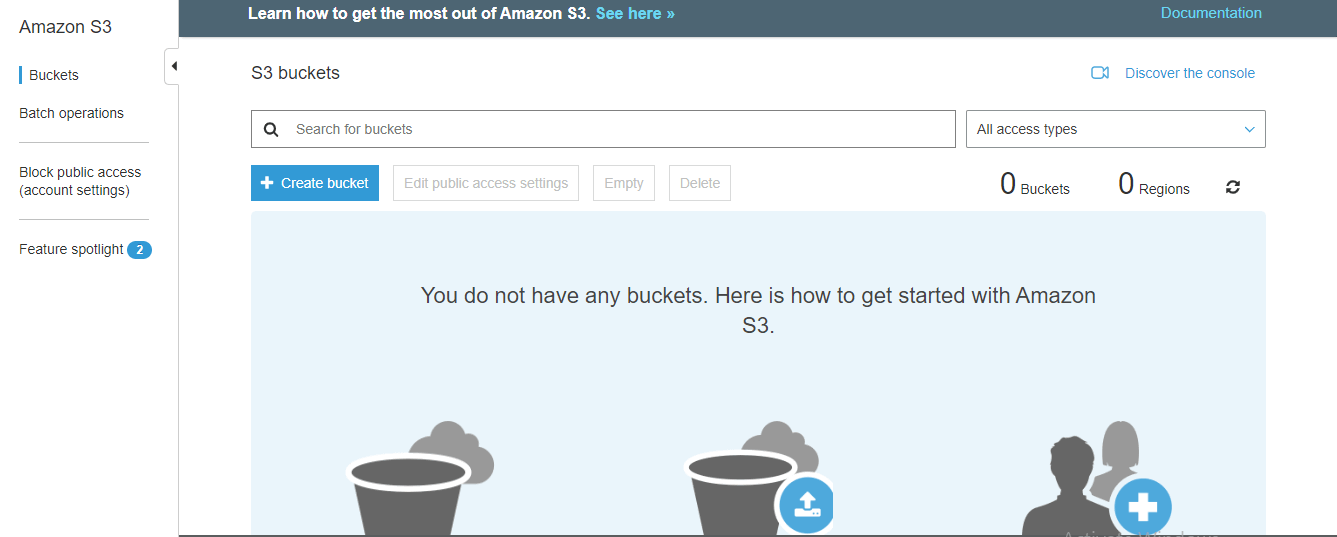
step - 2:
Click on Create bucket.
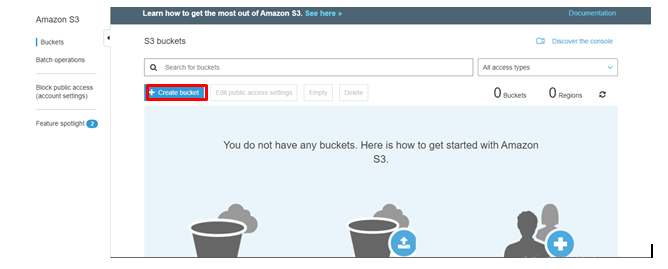
step - 3:
Fill the details and click on Create
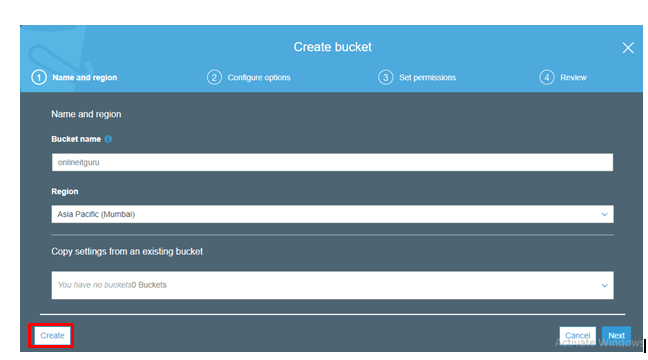
step - 4:
Click on Create Bucket
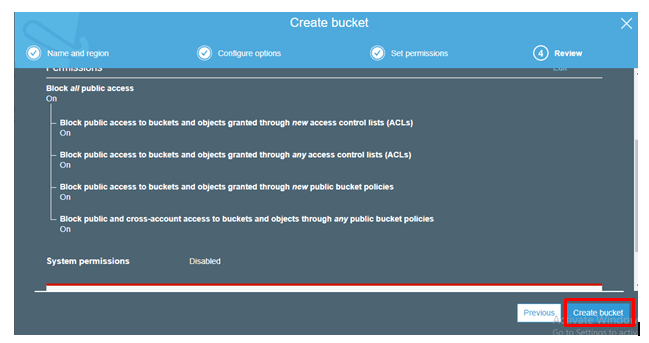
step-5:
Once created, click on the bucket that you have created. Then you will be entered into the following screen.
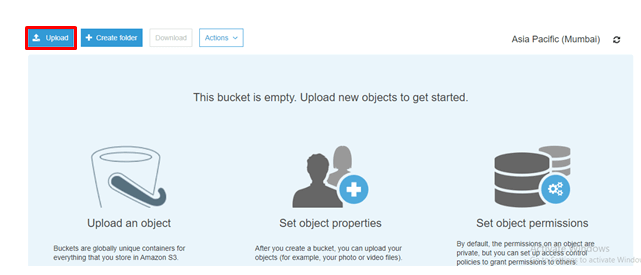
step - 6 :
Click on Add files.
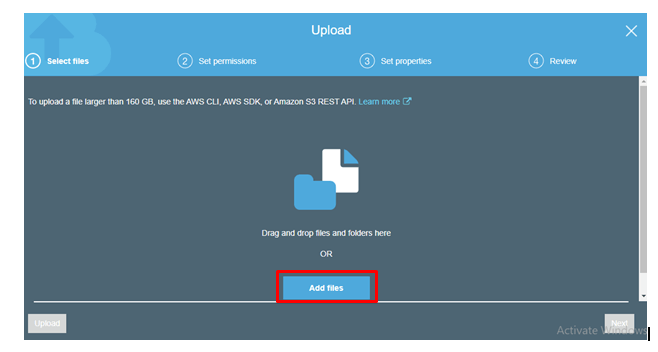
step - 7:
Add any file and click on Upload
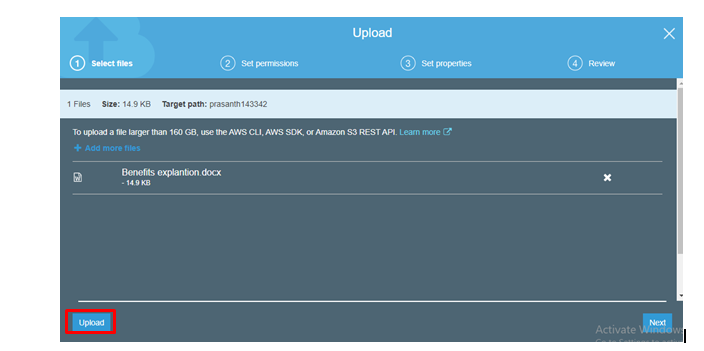
Likewise, you people can also add the folders (Drag and drop)
step - 8:
Click on the object, that you have created, then you will be entered in the following screen
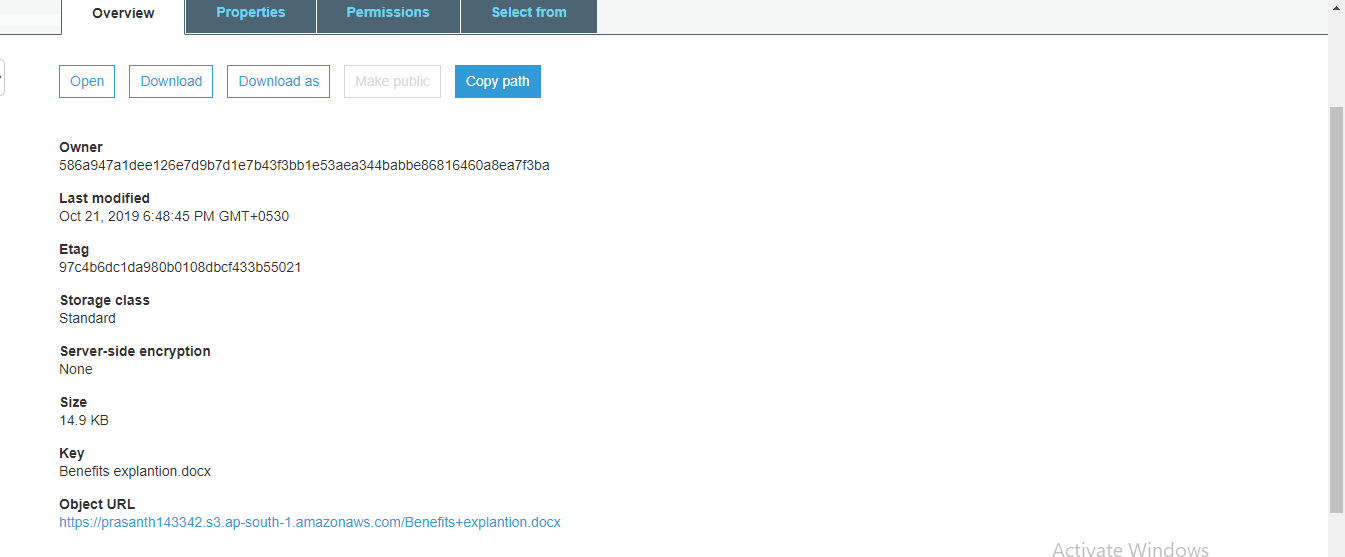
step - 9:
Click on the object URL and you will be entered into the following screen

step - 10:
So make it as public to remove this bug.
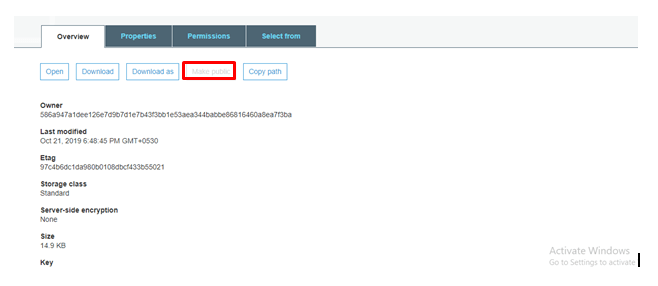
And you select an object/ folder you can see various options as shown below
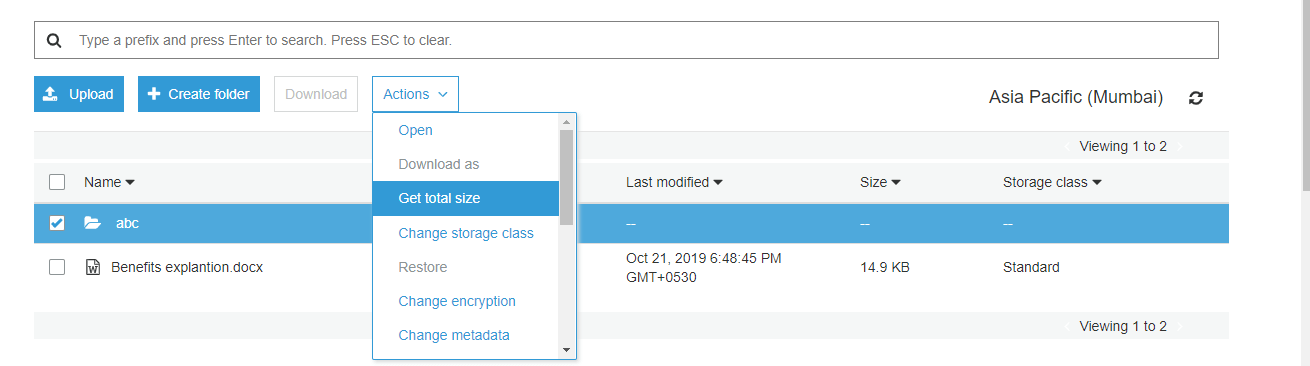
Note:
We cannot make the file public to all kind of file. And it is restricted to some kind of files.
Get those restrictions at AWS Online TrainingProperties:
What is object Versioning:
Object versioning provides the flexibility of storing the objects with the same names but with different version numbers. This prevents the unintended overwriting (or) object deletion.
let us see how the versioning works in detail
step - 1:
create an object and upload any file ( For instance, I'm using the .html file). Then you will be entering into the following screen.
step - 2:
Select the object and make it public. And then open the object using the URL. Then you will be getting the output as follows
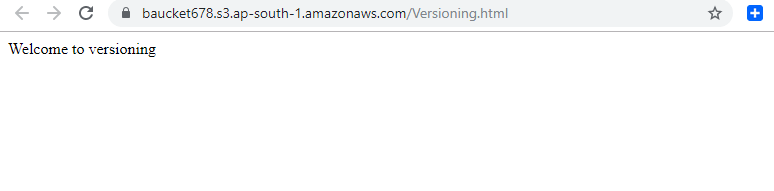
step - 3:
so now navigate to the properties tab and select versioning and click on enable and save it.
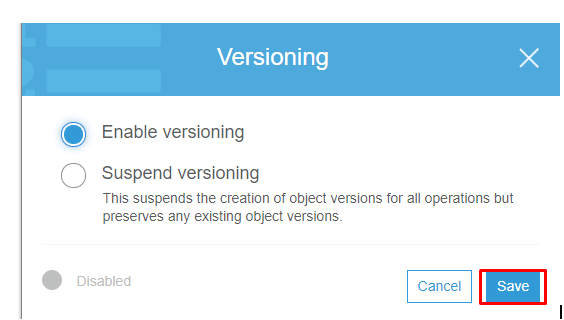
step -4:
Add some data to the existing file and save it
step-5:
Upload the file once again
step -6:
Open your bucket then you get activate show. Then you will get log as follows
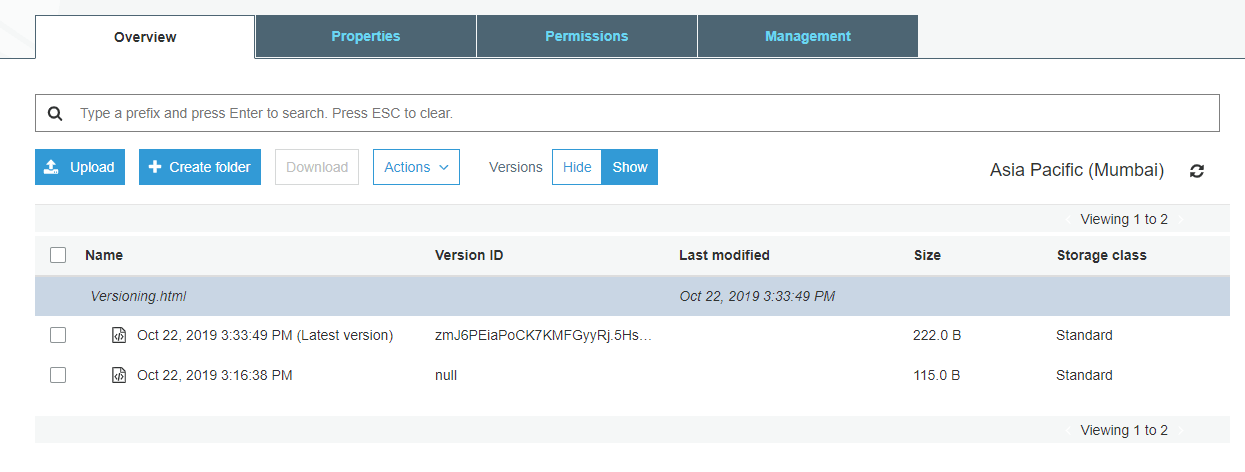
So once you observed the above screenshot, you can the two files in different timings. It means, for every change that you have made in the source file, a new version will be created
Note :
For every file updation, you must make the file as public. Else you cannot access the file
step -7:
So once you have done all this, then try to access the files. And in my case, ill get my screen as follows
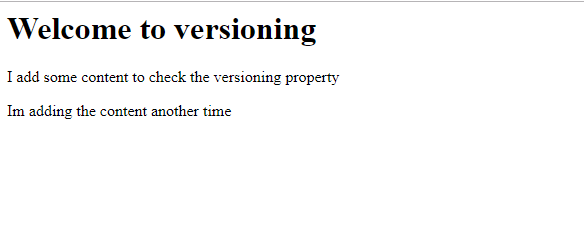
And if you navigate back to the object and click on properties, then you can see the screen as follows:
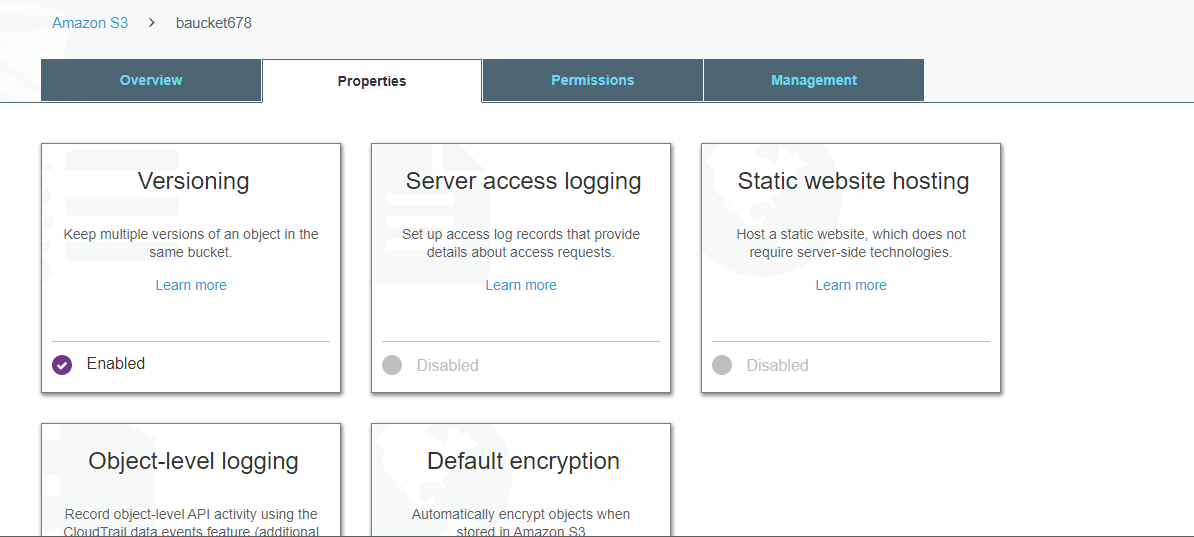
In the above screenshot, server access logging contains log details of various users in the amazon account
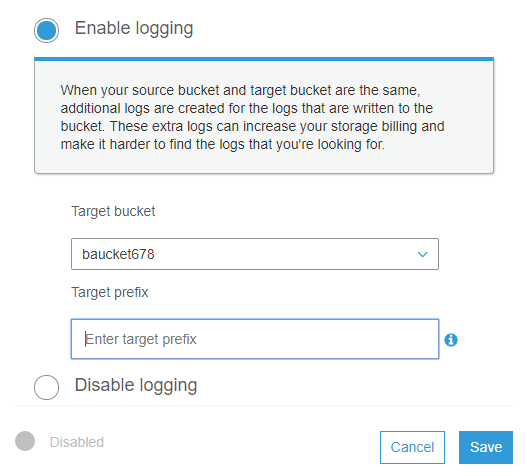
So click on the sever access logging and select Enable logging, select the bucket and click SAVE.
Static Website:
in the next column, we have an option static website. So we will now see how to launch the static website.
step -1:
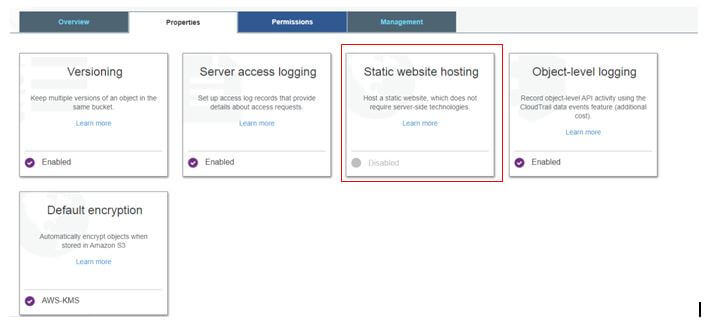
Navigate to S3, and select any bucket, go to properties and then click on static website hosting.
step - 2:
Select use this bucket to host the website and provide the names as shown below then save it.
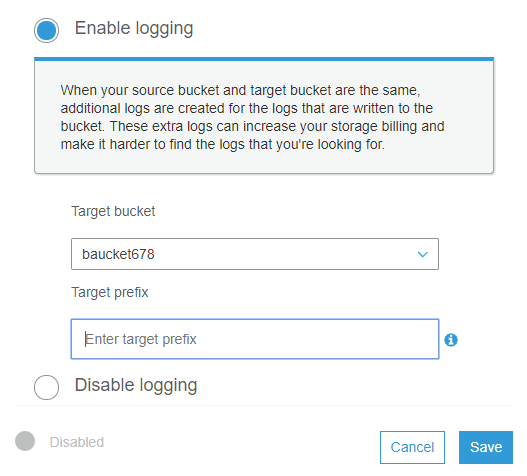
Note: Before saving your option, copy the endpoint in any text editor.
step - 3 :
Open any text editors like Notepad and create two HTML files like index.html and error.html as shown below
Index.html
Welcome to ONLINEITGURU AWS Tutorial
This page works good