Last Updated At 2020-06-15

Scalable
Hadoop basically has multi-node cluster to perform the big data computation .So if you want to increase processing speed you can add more cluster nodes.
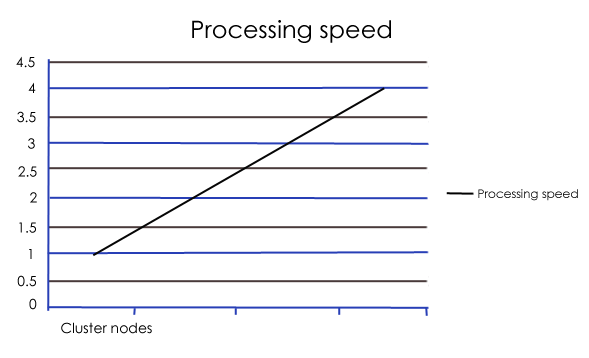
Fault tolerant
Hadoop has the provision to replicate input data on to other cluster nodes. In a scenario when there is a cluster node failure data processing can proceed to data stored on another cluster node.
Also if master node fails the data of master node is replicated at a safe place and then reused.
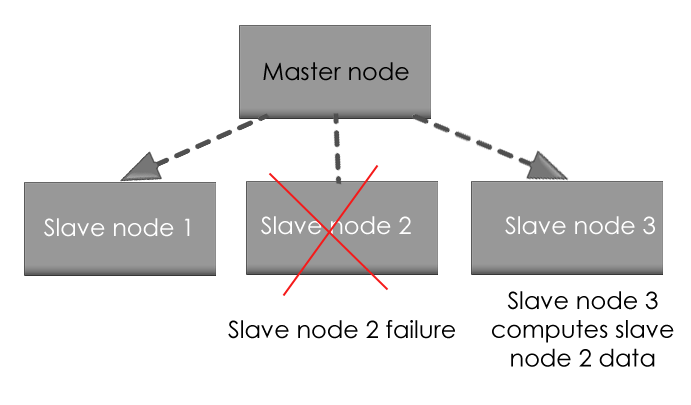
Handle variety of data
Hadoop can handle all types of data be it structured, semi-structured and unstructured.