
Machine Learning is an application of AI that focuses on the development of system programs that provides the ability to learn automatically. Machine Learning models are the mathematical representation of real-world processes. These models are the outcome of the training process which can be used for making predictions. Moreover, this training process continues until the model achieves its desired level of accuracy on the training data.
There are a number of Machine Learning models available. The Machine Learning methods are depended on the type of tasks they deal with. Furthermore, they are classified into Classification models, Regression models, and Clustering, Principle Component Analysis & Dimensional reductions.
Let us discuss Machine Learning models and their usage in detail in this blog.
Types of Machine learning models
The different types of Machine learning models based on the types of tasks are as follows.
Classification Models
The Classification model tries to draw a conclusion by observing several values. A classification model will attempt to predict the value of one or more outcomes. Besides, the outcome for classification is always variable. Moreover, there are many types of Classification models. Such as decision tree, logistic regression, random forest, multilayer perception, Naïve Bayes, one-Vs-rest, etc. A few of these models discussed as follows.
Decision tree: A decision tree under classification models is a way to make a decision by spitting the inputs into small decision pieces. Moreover, it involves some simple mathematics too. The tree is divided into decision nodes and leaves.
Moreover, the decision tree is part of the supervised learning algorithm useful for classification issues. It is a classifier with a tree-structure, where internal nodes show the features of a dataset, branches represent the decision rules and each leaf node shows the results.
Logistic regression: A logistic regression is a variation of linear regression. It attempts to calculate a dependent variable based on an independent variable. Moreover, it’s a type of classification useful to forecast discrete values based on the given variables. It also estimates the probability of the event happening by linking data to a “Logit Function”.
Random forest: This classification model is like a decision tree model. Here the questions that come forward include some randomness. This model is a combo of a decision tree model and here we get the collection of decision trees called Forest. Here, each tree provides a classification based on the attributes that are considered as a vote to that class. Therefore, the forest selects the classification with the most votes given by the trees.
Naive Bayes: The theory of Naïve Bayes is useful to detect or classify email whether spam or not. Bayes is a regular statistic where the concept is based on dependent probability. Moreover, the dependent probability is totally based on the chances of the outcome. This division technique is mainly based on Baye’s Theorem. Here, the Bayes classifier presumes that the existence of a specific feature within a class is unrelated to any other feature existing. Therefore, this model is easy and simple to develop and mainly useful in large data sets. Besides, it can perform better than any other models even in complex classification methods.
To get practical insights into ML models, Machine learning Online Course will help in this regard.
Regression model
Under Machine learning models, the regression refers to a certain set of problems that the output variable can take continuous variables. Predicting airlines ticket comes under this model approach. There are some important regression models commonly in practice such as linear regression, non-linear regression, and probabilistic model.
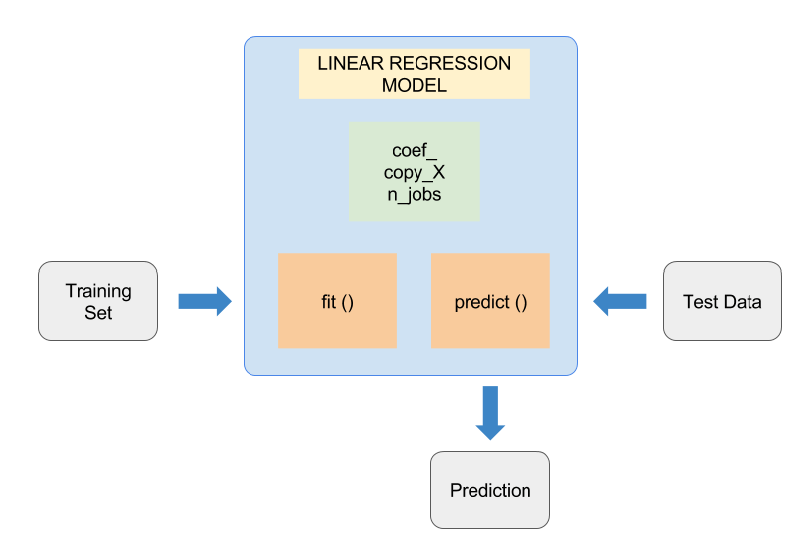
Linear Regression
Using “Linear Regression” we can compute the linear relation between two or more variables. On the basis of this relationship, we make predictions that follow the linear regression pattern. Moreover, this is useful for evaluating real values based on continuous variables where we will check the relation of independent and dependent variables. Here, the LR can be understood with our childhood learning example.
For instance, if we ask any child to arrange people within his class by the means of height and weight in a serial order. Then, he will check the parameters by simply arranging them in order of their height and weight. Furthermore, he will use a simple mathematical linear equation for getting the output. Here, it involves two different variables, and the intercepting lines on-axis. (Ex:Linear equation - Y= aX+b)
Further, linear regression is divided into two different types, such as; Simple Linear Regression, and Multiple Linear Regression. The Simple linear regression model is specified by a single independent variable whereas the multiple linear regression models specify multiple independent variables.
Support Vector Machine
This is a classifying method where SVM works as a powerful classifier useful in classifying the binary datasets. It classifies them into two distinctive classes. Besides, this is the most popular Supervised Learning algorithm. The aim of the SVM or support vector machine algorithm is to build the best line or decision boundary that can separate n-dimensional space into two different classes. This is much useful that we can easily put the latest data point within the exact category in the future. This decision boundary or line is called a Hyperplane.
There are two different types of SVM such as; Linear and Nonlinear.
Linear SVM:
This is useful for data separation linearly where-in case a dataset further subdivided into two different classes by using a single straight line. Hence, this data is called linearly separable data, and the classifier used here is the Linear SVM classifier. It isolates the data in a linear way.
Non-linear SVM:
This model is useful for data separation non-linearly. It means if a dataset cannot be separated by using a straight line. Then, this data is known as non-linear data, and the classifier used is known as the “Non-linear SVM” classifier.
||{"title":"Master in Machine Learning", "subTitle":"Machine Learning Certification Training by ITGURU's", "btnTitle":"View Details","url":"https://onlineitguru.com/machine-learning-course.html","boxType":"demo","videoId":"5t5sziaqqLA"}||
Clustering
The clustering under Machine learning models is the task of grouping similar objects together. The Machine Learning models help to detect similar objects without the intervention of human beings. Without having homogenous data, it is a little difficult to build Machine learning models. Moreover, there are different types of clustering models such as K means, K means ++, DBSCAN, etc. The clustering is further classified into different models.
- Connectivity models
- Centroid models
- Density models
- Distribution models
Dimensionality reduction
Dimensionality refers to the number of prediction variables useful to predict the independent variable. While in the real-world data sets, there are a number of variables. This huge number of variables may overfit the model. Moreover out of these numbers of variables, most of the variables don’t contribute equally towards the goal. There are some most common models of dimensional reduction that are in use. These are,
PCA- This approach creates less number of variables out of the huge number of predictions.
TSNE- It provides a lower-dimensional embedding of high data points that generate in the process.
SVD- It refers to singular value decomposition that is useful to decompose the matrix into small parts for efficient calculations.
Moreover, in dimensional reduction, there are few more methods that are useful. Such as a) Feature selection methods, b) Feature projection methods. The feature selection methods include filter strategy, wrapper strategy & embedded strategy. Furthermore, the feature projection method includes linear methods, non-linear methods, and tensor representations.
Deep Learning
Deep learning is the subset of ML and it deals with neural networks. Moreover, there are different types of deep learning models base on neural networks. They are,
- Convolution Neural networks
- Multi-layer perception
- Boltzmann Machine
- Recurrent neural networks
- Autoencoders
Moreover, there are some artificial neural networks such as feedback ANN, feed-forward ANN, and long short term memory networks.
Machine learning models for prediction
Machine learning models can be used for making various predictions. These predictions are most valuable for any business model. Besides, there are many kinds of predictions that machine learning professionals make in this regard. For example, we can make predictions of the stock market regarding stock prices, Sensex ups, and downs, market conditions, etc. Moreover, there are two basic types of approaches in stock market analysis. They are fundamental analysis and technical analysis.
Fundamental analysis- A fundamental analysis includes an analysis of the company’s future profitability and its asset size. It depends upon the company’s existing business environment and financial conditions. Moreover, the performance of business also an important thing here.
Technical analysis- The technical analysis includes some technical points. It involves reading the charts and graphs using statistical figures. Moreover, it identifies the changing trends in the stock market.
The machine learning models and approaches that apply in this regard are,
- Moving average
- Linear regression
- K-Nearest neighbors
- Auto ARIMA
- Prophet
- LSTM
Let’s discuss it in detail.
Moving Average
An average is the most common thing that we use in our day to day life such as doing some calculations. For example, we can calculate the average temperature of the past few days or the price of petrol/diesel that changes daily. Besides, this approach is very much useful for predicting market prices. Such as predicting the closing price of the market for every day close. Moreover, the usage of the moving average technique over a simple average is more beneficial to predict the latest set of values.
K-Nearest Neighbors
It is one of the most useful machine learning algorithms known as kNN. Moreover, this approach is based on the independent variables, where the kNN finds the similarity between the two data points. These are new and old data points.
The KNN model is useful for both classification and regression issues. But it's most useful in classification problems. Moreover, it’s a simple algorithm that stores the existing cases and classifies the new. It conducts this based on the votes given by its “k neighbors”. Hence, the case allocated to the class is most common among its kNN(s) computed by a distance function.
The use of kNN is easily mapped to our real lives where we can learn to know about an unknown person. Furthermore, we have to know that it is computationally expensive.
Auto ARIMA
ARIMA is a popular statistical method. It is useful for forecasting time series where these models use past values for predicting new values. Furthermore, the ARIMA model has three different parameters. These are;
- P (it refers to the past values that used to predict future values)
- Q (it refers to the past predicted errors that are useful to predict future values)
- D (this refers to the order of differencing)
ARIMA refers to “Auto-Regressive Integrated Moving Average”, a class of models that defines a given time series based on the past values. This data includes lags and lagged predictive errors. Therefore, the equation can be useful in predicting future values.
Moreover, any non-seasonal time-series that displays different patterns, can also be modeled or designed using ARIMA. This model is best characterized into three different models such as p, q, and d.
Moreover, the professionals use the Auto ARIMA model for making various predictions as the ARIMA models consume a lot of time for tuning parameters.
LSTM
This refers to the long short-term model under Machine learning models for the prediction approach. This model is useful widely in making sequence predictions. Moreover, this model helps to store past information that is important and neglects the unimportant one. The LSTM model uses three gates in its approach. These are; the input gate, the forget gate, and the output gate.
Furthermore, the stock market prices are also affected by global happenings. It depends upon the trends but sometimes it is difficult to make predictions based on uncertain things.
||{"title":"Master in Machine Learning", "subTitle":"Machine Learning Certification Training by ITGURU's", "btnTitle":"View Details","url":"https://onlineitguru.com/machine-learning-course.html","boxType":"reg"}||
Conclusion
Thus, the different types of Machine learning models approach to solve different issues. These models help in various ways. Machine learning is very useful in different fields. Using this many businesses can achieve their goals and makes their business better.
To get more knowledge of ML models to practically skilled with various Machine learning techniques and tools. One can opt for Machine Learning Online Training from industry experts. This learning will help to enhance skills and paves the way for a better career.