
Hadoop is an open-source Java framework used to store and process a large amount of data under a distributed environment. Generally, unstructured data is distributed among the clusters and it is stored for further processing. Hadoop architecture is a package that includes the file system, MapReduce engine & the HDFS system. Moreover, the Hadoop architecture allows the user to perform parallel processing of data with different components. Such as; Hadoop HDFS, Hadoop YARN, MapReduce, etc.
Hadoop architecture includes master-slave topology. It includes two major nodes such as master nodes and slave nodes. The master node assigns several tasks to the slave node to perform. The slave node has the responsibility to perform actual computing. Moreover, the master node stores only metadata, whereas the slave node stores the actual data for processing. All this is based on the distributed data file system.
Hadoop architecture and components in detail
Hadoop architecture includes different types of technologies and components. It helps to solve many complex issues easily. While data processing, when the data files are large they are stored upon different servers. Later the mapping is done to reduce further operations and functions. Moreover, the Hadoop architecture includes three major kinds of layers. Such as-
- HDFS
- YARN
- MapReduce
HDFS
HDFS refers to the Hadoop Distributed File System. The HDFS helps to store data of Hadoop. It divides the large data into small units known as blocks and stores them on a distribution basis. The architecture includes a NameNode and multiple DataNodes as its major components. Besides, the NameNode performs like a master node and the DataNodes works as slave nodes.
NameNode- The NameNode runs on the master server that is responsible for the Namespace management. Moreover, it regulates the file access by the clients and stores the metadata. It requires very little storage space and computing resources to perform any task. The system also keeps tracking of different blocks with respect to DataNode. Besides, it simplifies the system architecture.
DataNode- The DataNode runs on the slave node that stores the actual business data. Moreover, it splits the data into several blocks and stores on the slave machines for further process like create, delete, and replicate data. Besides, it acts upon the directions of NameNode.
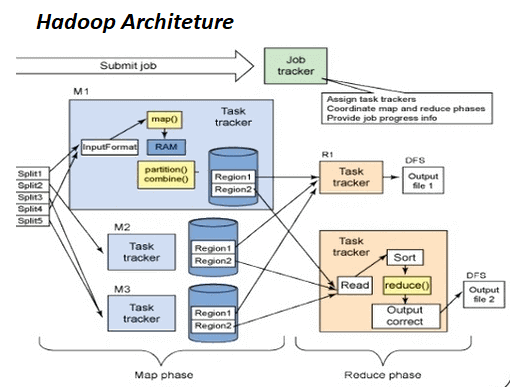
Task tracker- The Task tracker works for a job tracker under the slave node. Its job is to receive tasks and codes from the Job tracker and applies the same on the file. Moreover, this task is also called Mapper.
Map & Reduce- The Map & Reduce layer emerges as the client application submits the MapReduce work to Job Tracker. In response to this, the Job tracker sends a request to the respective task tracker. Besides, when the task tracker fails anyhow, it reschedules the part of the task.
To get more insights into Hadoop architecture, Hadoop Admin Online Course will help easily.
YARN
YARN refers to Yet Another Resource Negotiator. This component is also popular as the resource management layer of Hadoop architecture. It is like the brain of the Hadoop ecosystem that handles all the task performances. These tasks include job scheduling, resource allocation, activity process, etc. There are two major components of YARN, such as Node manager & Resource manager. Besides, the Resource manager passes the various requests to the Node manager. Here, each Data Node is responsible to perform the tasks. The resource manager further divides into two more important components such as Scheduler & Application manager.
Moreover, there is an Application manager also that manages the application lifecycle well along with scheduling tasks. Besides, YARN is the best resource of utilization where the user can run different Hadoop applications. This system uses the YARN framework without enhancing many workloads. The YARN component includes various features such as cluster utilization, multi-tenancy, compatibility, and scalability.
MapReduce
MapReduce is the combination of two components, namely, map and reduce. Moreover, it consists of the major processing components. It helps to write large data sets that use parallel & distributed algorithms under the Hadoop architecture. The Map component performs various tasks such as grouping, sorting, and filtering of operations. Moreover, the Reduce component performs to summarize and gather the results produced by the Map component.
The Map task functions include load, parse, transform, and filter the data. Besides, the map task runs on the node where the actual data is present. Moreover, the map tasks run under different phases. These are the record reader, map, combiner, and partitioner. Further, the reduced task also includes different phases such as shuffle & sort, reduce, output format, etc.
The whole concept of MapReduce explains that the map function sends a query request to different data nodes to process whereas Reduce collects the results.
Furthermore, there are many other components of the Hadoop ecosystem. These are as follows.
Apache Pig
An Apache Pig is a kind of language that is useful to process applications in parallel with large data sets under Hadoop architecture. This is an alternative for the Java programming language. Like Java & JVM, there are two major components of Pig such as Pig Latin & Pig run time. The Pig Latin includes SQL commands with less coding. Besides, a non-tech person also can use this component. Moreover, the Map-reduce job executes behind the Pig Latin functions. Here, the compiler performs to convert the Latin into map-reduce job tasks. This useful for complex task processing & also requires different data operations. Furthermore, it also supports various programming languages such as Ruby, Python, Java, etc.
The working of the Pig component is based on loading data where we use the “load” command. Later, we can execute different functions like data grouping/allocation, filtering, combining, etc. Further, we can bring the data on screen or can store the output within HDFS as per the need.
Mahout
The Mahout component under Hadoop architecture is mostly useful for Machine Learning. It provides the environment set up for developing various Machine Learning applications. Moreover, Machine learning applications learn from past experiences just like Artificial Intelligence performs. Mahout can perform various operations like clustering, filtering, and collaboration.
HBase
HBase is known as an open-source non-relational database. It can handle any type of data and supports all major data types under the Hadoop system. This system runs on the HDFS system which is also working on distribution storage supports large data sets. The HBase is written in Java and its applications are written using REST, Avro, etc. Moreover, HBase is developed to solve the problems. In this system, a small amount of data is searched over the large database. The HBase component is designed to store structured data. It includes various rows and columns.
||{"title":"Master in Hadoop Admin", "subTitle":"Hadoop Admin Certification Training by ITGURU's", "btnTitle":"View Details","url":"https://onlineitguru.com/hadoop-online-training-placement.html","boxType":"demo","videoId":"ms7Mw3GLGrU"}||
Zookeeper
To manage the Hadoop architecture clusters Zookeeper is useful. It provides various reliable, fast, and organized operations and services. The Zookeeper provides a speedy and manageable environment. The system saves a lot of time by performing various tasks such as grouping, naming, maintenance, and synchronizing operations in less time. Moreover, it offers the best solutions for many Hadoop use cases. Many big brands and MNCs like eBay, Rackspace, etc are using Zookeeper for their business operations.
There are some other components of Hadoop architecture such as Oozie, Ambari, etc.
Oozie
The Apache Oozie is a scheduler system within Hadoop architecture that runs in a Java servlet container. Using this, we can pipeline the programs in a sequential manner as per requirement. It helps to run and manage various Hadoop tasks. Further, it allows integrating various complex tasks to be run in a serial order that helps to get the required result. Moreover, it strongly integrates with another Hadoop stack to support different tasks such as Pig, Hive, etc. It’s a Java web app with open-source availability.
Hence, the Oozie component includes two different tasks;
Oozie workflow: A workflow is a group of actions organized in a way to perform the jobs in a sequence. We can give the best example of the workflow of a relay race. Here, a person starts running at one end that ends with another person on the other end.
Oozie Coordinator: The coordinator runs the workflow tasks based on the predefined schedules and data availability.
Ambari
This is an open-source/free to use software that helps to manage the Hadoop operations. It helps in managing the Hadoop cluster’s monitoring, handling, and provisioning, etc.
The Hadoop cluster management within the Hadoop architecture ecosystem acts as a central management system. It helps to start, stop, and reset up Hadoop services across the clusters.
Monitoring refers to here is it provides the monitoring services like system health and status. It buzzes the alarm when anything goes wrong within the system.
The provisioning part guides us in installing the Hadoop services across different hosts step-by-step. Moreover, Amabari is capable of handling the configuration of Hadoop services across the clusters.
Apache Flume
The Hadoop architecture component Flume helps in various ways. It gathers, combines, and transmits large data sets from the source and gets back the output to the HDFS. Flume mainly works on the fault tolerance mechanism. Moreover, it helps its users to get the data from different servers right away into this framework.
Apache Drill
This is a low latency allocated query engine designed to compute thousands of nodes and issues. The data may be of large size but it can handle. Moreover, the special skill in this component is that it avoids cache data and also frees up space. This component within the Hadoop architecture system allows extendability across the clusters. It also provides data in a structural form that is easy to understand. Hence, users don’t require to build a metadata table as it doesn’t have central metadata.
Apache Sqoop
This is a front-end interface of Big Data that works as a data loader. It helps in moving large data sets from Hadoop to RDBMS. It replaces the script useful for importing and exporting data. Hence, it also performs an ETL process in this regard.
Thus, these are the additional components within Hadoop architecture other than mentioned above. We can use them for different purposes within the clusters for handling large data and many other functions.
Features of Hadoop
There are many features of Hadoop. These are as follows.;-
- This architecture brings flexibility in data processing activities. Hadoop manages different kinds of data such as structured and unstructured, encodes, formatted, etc.
- Hadoop is a highly scalable platform. Moreover, it is an open-source platform. It runs on standard software of the industry which makes it highly scalable.
- It helps in faster data processing compared to other platforms. Moreover, the Hadoop ecosystem is very robust and dynamic.
- Moreover, this is very cost-effective. It operates various parallel computing systems that reduce the cost as per storage.
- This system has also tolerated any faults. While any of the systems collapses or fails, the data is still available on another system.
- Being an open-source project, its source code is available cost-free. This is useful in inspection, transformation, & analysis, of the code and enables businesses to change the code as per need.
- The data replication within the cluster helps data reliably stored on the system’s cluster despite the device failures. That means if the system goes down then also the data is stored reliably due to Hadoop architecture.
- In Hadoop architecture, the cluster includes more than two NameNodes running in a standby set up. The node that is actively work called NameNode and the inactive one or passive mode is the standby node that helps to edit the Active NameNode activities. Moreover, when the active node fails to act, then the stand by node takes responsibility.
- Hadoop offers cost-effective features to its users. Due to having the commodity hardware nodes of the Hadoop cluster, it offers lesser costly solutions of data storage and process. And due to the open-source, it (Hadoop) doesn’t have any license to use specifically.
- Hadoop architecture also includes the data locality concept that moves computation logic to the data instead of doing vice-versa. This feature helps Hadoop to minimize the usage of the bandwidth of a system.
- Data feasibility for users as it offers to deal with different data formats.
- Helps to run large-scale data sets through the HDFS system within the Hadoop architecture. It also runs data batch-wise.
||{"title":"Master in Hadoop Admin", "subTitle":"Hadoop Admin Certification Training by ITGURU's", "btnTitle":"View Details","url":"https://onlineitguru.com/hadoop-online-training-placement.html","boxType":"reg"}||
Conclusion
Thus, the above details explain the Hadoop architecture and its various components. The Hadoop ecosystem carries various components and features that help to perform various tasks. Moreover, it works on a distributed data system. In this large data sets are segregated into small units. It makes the task complete in lesser time. Many different features of this ecosystem make it famous among the programming languages.
To get practical insights into learning Hadoop and its components one can opt for Hadoop Admin Online Training from industry experts. This learning may help to develop the latest skills in this regard which may enhance the scope for a better future.