
There are six primary needs that Big Data technologies address:
1. Distributed Storage and Processing
Big data deals with supporting processing large volume of multi structured data.
Big data technologies provide distributed fault tolerant file system and massive data processing across a cluster of servers
They provide batch processing for throughput.Like Microsoft Azure is used for processing petabyte scale volume of multi-structured data
Below are few more products/vendors
• Hadoop: YARN, NoSQL,• Spark• Cloudera• DataStax• Hortonwork• Databricks• IBM® BigInsights• Amazon Web Services (AWS)• Google™ Cloud Platform
Apache HadoopApache Hadoop is one of the leading framework for data storage.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using a simple programming model.
The Hadoop framework is a collection of tools over HDFS/MapReduce for building Big Data applications.
HDFS
HDFS is a distributed, fault-tolerant file system used to back the computation of Big Data.
MapReduce
MapReduce is a distributed, fault-tolerant, system used for parallel programming
Apache SparkThe Spark framework performs general data analytics on distributed computing clusters like Hadoop.
It provides in-memory computations for increased speed and data processing over MapReduce.
It runs on top of an existing Hadoop cluster, can access the Hadoop data store (HDFS), and can process structured data in Hive and streaming data from sources such as HDFS, Apache Flume.
Are you interested in learning Big Data then Connect to OnlineITGuru and get a Professional Big data training.
2. Non-Relational database with Low latency
Low latency allows means very less unnoticeable delay in input being processed and the corresponding output.
Because of the huge size and lack of structure traditional relational-based databases (RDBMS) cannot handle Big Data. Big Data requires a more flexible non-relational structure that supports fast access to data for processing.
There is no NoSQL database that can meet this need.
NoSQL is basically not only SQL database.
Distributed and designed for large-scale data storage and massively-parallel data processing across a large number of commodity servers. It can be used for dynamic and semi-structured data
Relational databases use ACID properties that is Atomic, Consistency, Isolation and Durability for ensuring the consistency of data, but No SQL use BASE.
BASE is Basically Available, Soft state, and Eventual Consistency.
Eventual consistency is conflict resolution when data is in motion between nodes in a distributed implementation.
Companies like Facebook and LinkedIn use NoSQL
The different products and vendors providing NoSQL
Example: MongoDB, Amazon Dynamo DB
Non-relational databases have special features to handle Big Data.
Relational databases are predefined. They are also transactional and use SQL and are relational.
Non-relational (NoSQL) databases are flexible, and scalable. Non-relational databases are also programmable and SQL-like.
Below are special features non-relational database can used to handle big data
- Key Value Pairs
The Simplest of NoSQL database use key-value pair (KVP) mode.
| Key | Value |
| LinkedinUser12Color | Green |
| Facebookuser34color | Red |
| TwitterUser45Color | Blue |
If you need to keep track of the of millions of users, the number of key-value pairs associated with them can increase exponentially
Examples: One widely used open source key-value pair database is called Riak
- Document-Based DB
There are basically two types of document databases. One is basically for document style contents like Word files, complete web pages and other is for storing document components for permanent storage as a static entity or for dynamic assembly of the parts of a document. The structure of the documents and their parts are in JavaScript Object Notation (JSON)
Example: MongoDB
MongoDB is composed of databases containing “collections which are composed of “documents,” and each document is composed of fields.
- Column-Oriented DB
Traditional relational database are row-oriented as data in each row of table is stored together.In columnar database data is stored across rows that is columnar or column oriented database.
Examples:
| Column 1 | Column 2 | Column 3 | Column 4 |
- Graph-Based DB
In Graph-Based DB data is structured in graphs that is node relationship rather than in tables.
The node relationship structure is useful when dealing with highly interconnected data and that kind of navigation is not possible in traditional RDBMS due to the rigid table structure.
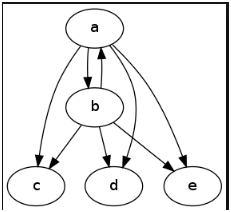
A graph database might be used to manage geographic data for telecommunication network providers
Examples: Neo4j is one of the most widely used graph databases.
Check the OnlineITGuru Big Data Hadoop Training now!3. Streams and Complex Event Processing
One of the major characteristic of big data is the event based data such as social media posts and news stories.
So streaming this event based multi-structured data and monitor and analyzing this streaming data in order to identify and respond to changing circumstances in real time is major characteristic of big data technologies Specialty Data Types
It is basically used in online portals for real time ads and promotion
The most common products and vendors for it are Apache Flume, Spark
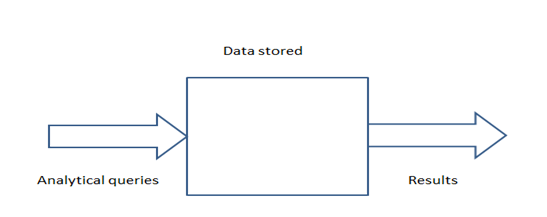
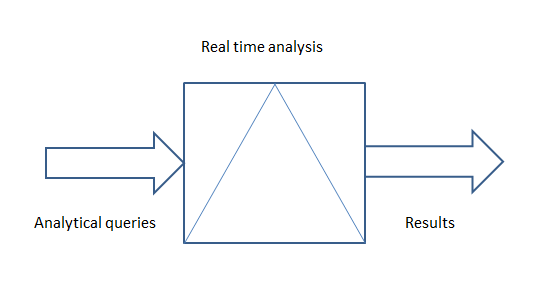
In traditional approach data is stored and analyzed but in the big data approach it is analyzed in real time
Traditional approach:
Big Data approach:
4. Data Processing of Special big data data-types
Big data deals with semi – structure, highly complex and densely connected data types.
The different data types are imagery used in satellites, audio and video files used in multimedia, text in newspaper
In fact multi -dimensional processing models have been developed and refined for managing these data types
Basically they are the graph database for understanding the real time querying and analysis of complex relation such as social graphs.
The different products and vendors are Neo4j and Allegro Graph
Specialty data is processed via Java and many graph algorithms
5. In-Memory Processing
This basically overcomes traditional system bottlenecks of disk read/write.
Here database resides in memory sometimes which is distributed across clusters
In memory processing is all about speed of processing at large scale:
• Distributed in-memory cache access• Distributed in-memory Online Analytical Processing (OLAP)
It can be used to deal with high volume of sensor data for real time analysis
Example: Product and vendor – Apache Spark
6. Reporting Layer:
To capture and communicate business understanding and knowledge from Big Data analytics, we must move from standard reporting to more sophisticated visualization.
Visualization is presenting information in such a way that people can use it effectively.
This involves technologies used for creating images, diagrams, or animations understand, and improve the results of Big Data analysis.
Traditional reporting are tables, graph, charts and dashboard.
Big data analytics have to deal with poly-structured data regardless of size, location and incoming speed.
Examples:
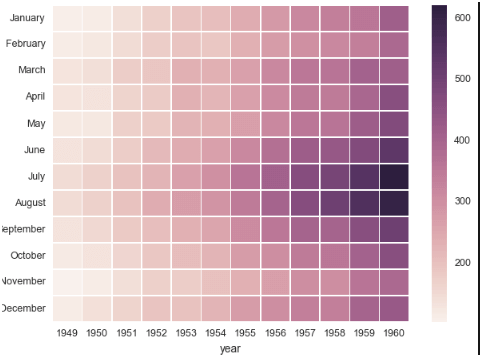
Heat MapA heat map uses color element to represent data value. Patterns in concentration can be shown using the color element. This is electricity consuming chart used throughput. It becomes easy to compute when it was used more or less
Tag Cloud
The words that appear more frequently will be larger than those which are used less frequently. A reader is quickly able to perceive the most important concepts represented in large text.

Big Data Roles
Below are few prominent roles that work with big data
| Role | Description |
| Hadoop Developers | Hadoop developers write map-reduce programs using Java, Python™, and other technologies including Spark™, Hive, HBase, MapReduce, Pig, and so on. |
| Big Data Solutions Architect | A Big Data Solutions Architect guides the full life cycle of a Hadoop® solution, including requirements analysis, platform selection, technical architecture design, application design and development, testing, and deployment. |